Introduction¶
The gcLDA model is a generalization of the correspondence-LDA model (Blei & Jordan, 2003, “Modeling annotated data”), which is an unsupervised learning model used for modeling multiple data-types, where one data-type describes the other. The gcLDA model was introduced in the following paper:
where the model was applied for modeling the Neurosynth corpus of fMRI publications. Each publication in this corpus consists of a set of word tokens and a set of reported peak activation coordinates (x, y and z spatial coordinates corresponding to brain locations).
When applied to fMRI publication data, the gcLDA model identifies a set of T topics, where each topic captures a ‘functional region’ of the brain. More formally: each topic is associated with (1) a spatial probability distribution that captures the extent of a functional neural region, and (2) a probability distribution over linguistic features that captures the cognitive function of the region.
The gcLDA model can additionally be directly applied to other types of data. For example, Blei & Jordan presented correspondence-LDA for modeling annotated images, where pre-segmented images were represented by vectors of real-valued image features. The code provided here should be directly applicable to these types of data, provided that they are appropriately formatted. Note however that this package has only been tested on the Neurosynth dataset; some modifications may be needed for use with other datasets.
Notation¶
| Notation | Meaning |
|---|---|
 , , 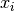 |
The 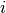 th word token and peak activation token in the corpus, respectively th word token and peak activation token in the corpus, respectively |
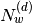 , ,  |
The number of word tokens and peak activation tokens in document  , respectively , respectively |
 |
The number of documents in the corpus |
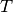 |
The number of topics in the corpus |
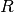 |
The number of components/subregions in each topic’s spatial distribution (subregions model) |
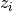 |
Indicator variable assigning word token to a topic |
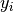 |
Indicator variable assigning activation token to a topic |
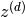 , , 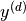 |
The set of all indicator variables for work tokens and activation tokens in document |
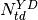 |
The number of activation tokens within document that are assigned to topic 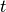 |
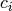 |
Indicator variable assigning activation token to a subregion (subregion models) |
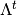 |
Placeholder for all spatial parameters for topic |
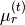 , , 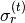 |
Gaussian parameters for topic |
 , ,  |
Gaussian parameters for subregion  in topic :math:`t`(subregion models) in topic :math:`t`(subregion models) |
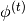 |
Multinomial distribution over word types for topic |
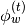 |
Probability of word type  given topic given topic |
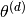 |
Multinomial distribution over topics for document |
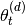 |
Probability of topic given document |
 |
Multinomial distribution over subregions for topic (subregion models) |
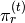 |
Probability of subregion given topic (subregion models) |
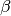 , ,  , , 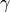 |
Model hyperparameters |
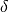 |
Model hyperparameter (subregion models) |